Datapandemin
Coronapandemin har format de senaste två åren på alla möjliga sätt. En sak som jag som statistiker inte kunnat undgå att lägga märke till är hur statistik, i form av statistik kring pandemin, plötsligt blivit förstasidesnyheter. Media och folk i allmänhet diskuterar siffror på ett sätt vi nog aldrig har sett förut:
- Är den senaste veckans ökade smittspridning tecken på en ny våg? Kommer spridningen istället att plana ut eller till och med gå ned igen?
- Hur ser utvecklingen ut de senaste månaderna? Vad är tillfälligt brus i data och vad är en trend?
- Kan man jämföra siffrorna för antalet smittade i olika länder, om rutinerna för testning ser olika ut? Testar man mindre så hittar man ju färre fall.
- Hur ska man jämföra siffrorna för andelen vaccinerade i olika länder? Ska man titta på andelen vaccinerade i olika åldersgrupper? I hela befolkningen?
Det här är den sortens frågor som vi statistiker jobbar med och tänker på varje dag. Att de uppmärksammas i den allmänna debatten är jättebra. Tillgång till bra och rättvisande data är i många fall A och O för att kunna fatta rätt beslut – men det räcker inte med att bara ha bra data, vi måste dessutom ställa rätt frågor och titta på data på rätt sätt. Där är statistikens verktygslåda och sätt att tänka ovärderlig.

För att göra all data kring pandemin begriplig försöker vi visualisera den i olika grafer. Vi möts varje dag av olika kurvor och figurer som visar antal, andelar och utveckling över tid – och inte bara i nyheterna.
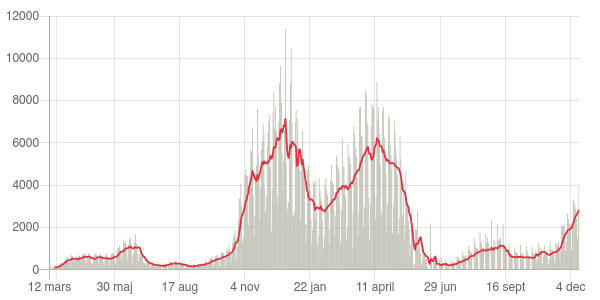
Intresset för datavisualisering har nyligen lett Washington Post till att starta ett nyhetsbrev om grafer som syns i nyhetsflödet. Brittiska Royal Statistical Society har i sin tur publicerat en rad intervjuer där de försöker lyfta fram statistiken och statistikers viktiga roll under pandemin.
Det finns nog mycket vi kommer att ta med oss från pandemiåren. Nya vanor, erfarenheter av distansarbete, insikter om hur samhället ska byggas för att kunna hantera oväntade händelser. Jag hoppas att en av de saker vi tar med oss är användandet av statistik och datavisualisering och vanan att ställa frågor kring vad det egentligen är olika siffror visar.
- Behöver ni hjälp med att tolka era data? Jag erbjuder konsulttjänster inom dataanalys. Kontakta mig för att få veta mer.
- Vill du lära dig mer om statistik och datavisualisering? Ta en titt på mina kurser i statistik med R.
