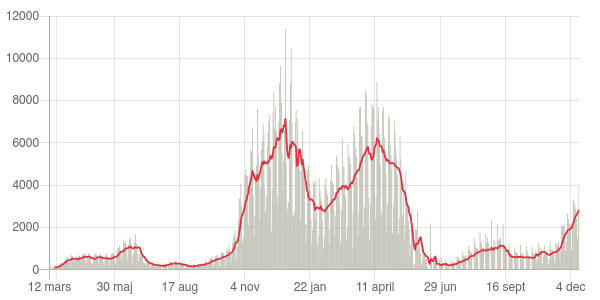
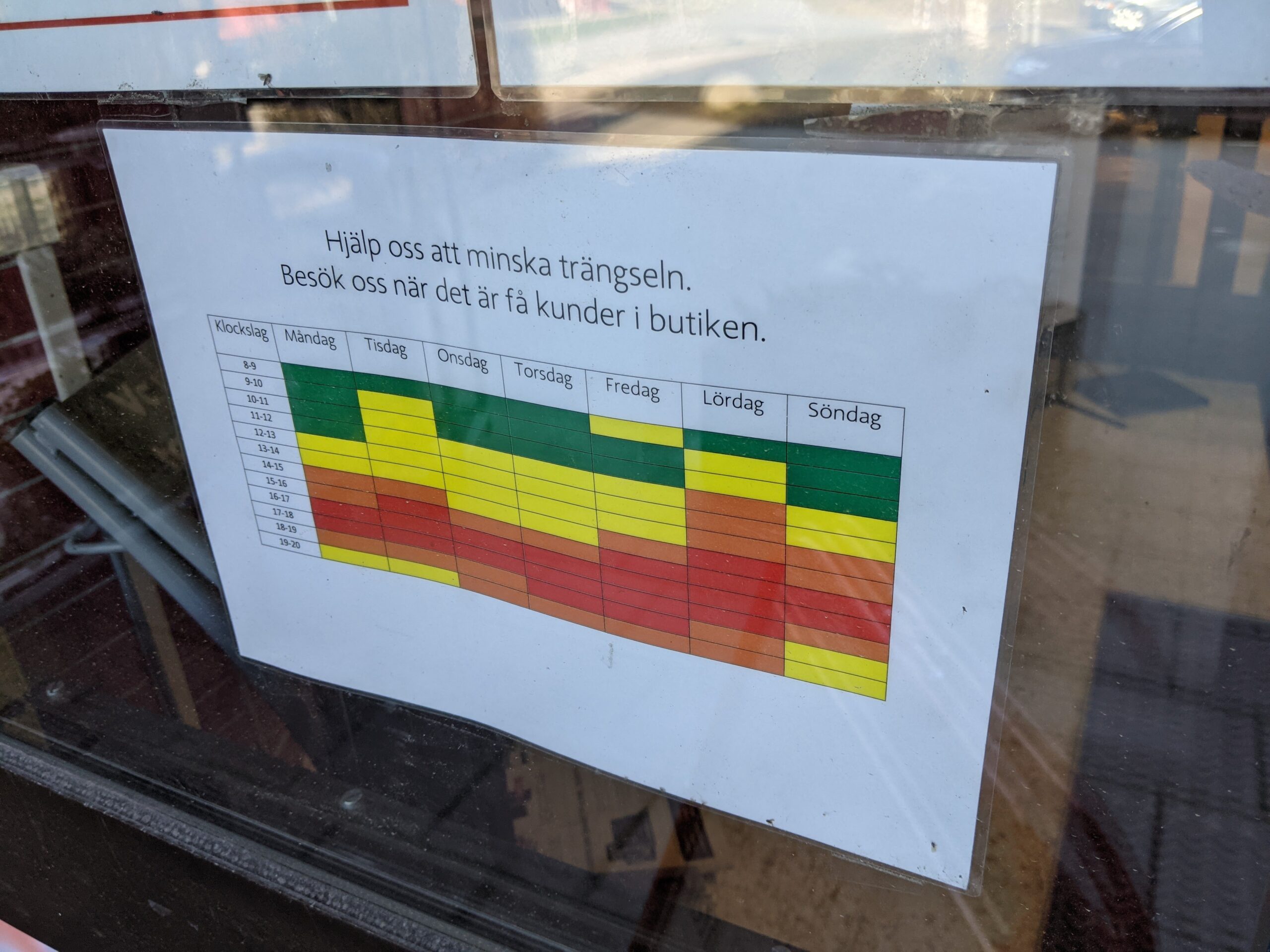
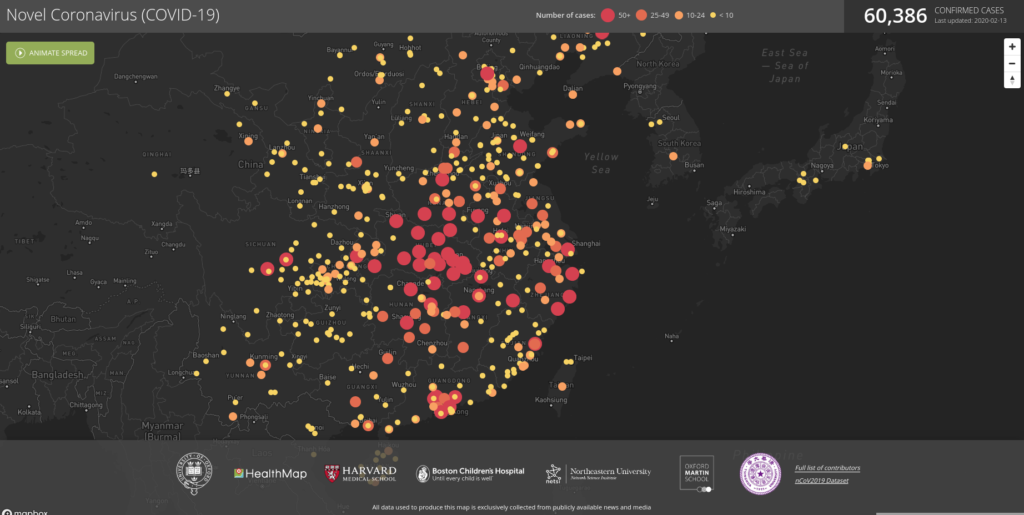
Många missförstår hur AI ska användas
Det händer många spännande saker inom AI-utvecklingen. Mycket av nyhetsrapporteringen kretsar kring framstegen som de amerikanska jättebolagen gör med modeller som OpenAI:s ChatGPT och Googles Gemini. Det är stora språkmodeller som kan svara på frågor, redigera text, skriva kod och skapa bilder. Ofta funkar det bra, men ibland blir det pannkaka av alltihop.
Stora språkmodeller i all ära. Även om de är intressanta så är det inte där det stora värdet i AI ligger just nu. För de allra flesta företag och organisationer är det istället enklare och mer specialiserade modeller som gör verklig nytta. Modeller som automatiserar långtråkigt rutinarbete och ofta gör jobbet bättre än människor. Bland exempel jag själv har jobbat med finns t.ex. AI-system som upptäcker sjukdomar hos mjölkkor innan människor kan se dem, modeller som hjälper bibliotekarierna på Karolinska institutets bibliotek att klassificera forskningsartiklar utan manuellt arbete och system som automatiskt granskar ritningar åt tillverkningsindustrin.
Det här var huvudbudskapet när jag för några veckor sedan besökte Uppsala universitet som en av fem föredragshållare på matematiska institutionens alumnevent om AI. En riktigt trevlig dag, med intressanta föredrag och givande diskussioner. Ser fram emot mer sådant under det kommande året!

- Jag erbjuder konsulttjänster, föredrag och utbildningar inom AI, maskininlärning och statistik. Kontakta mig för att få veta mer.